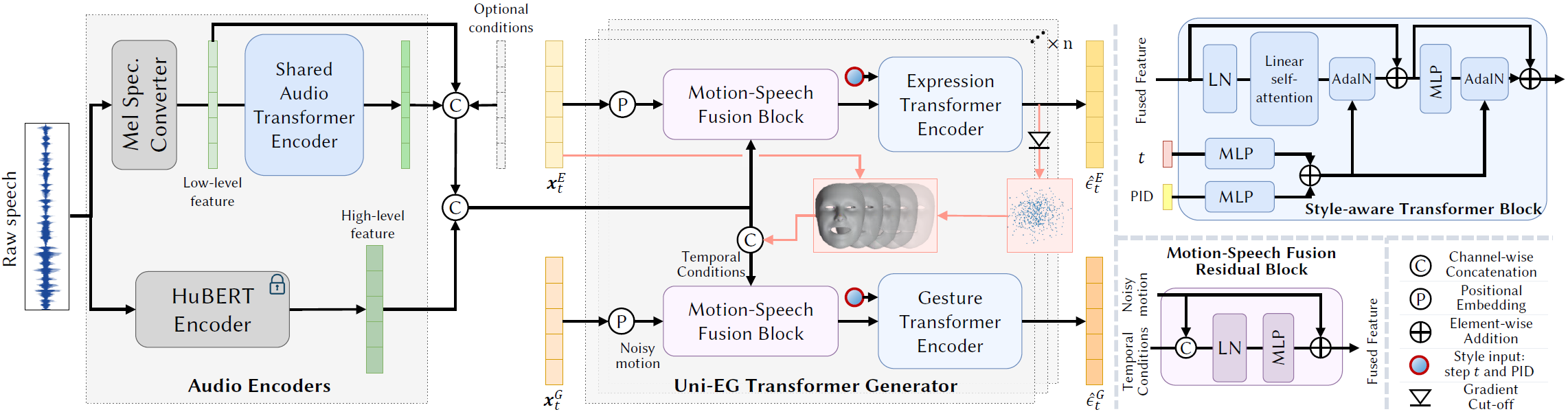
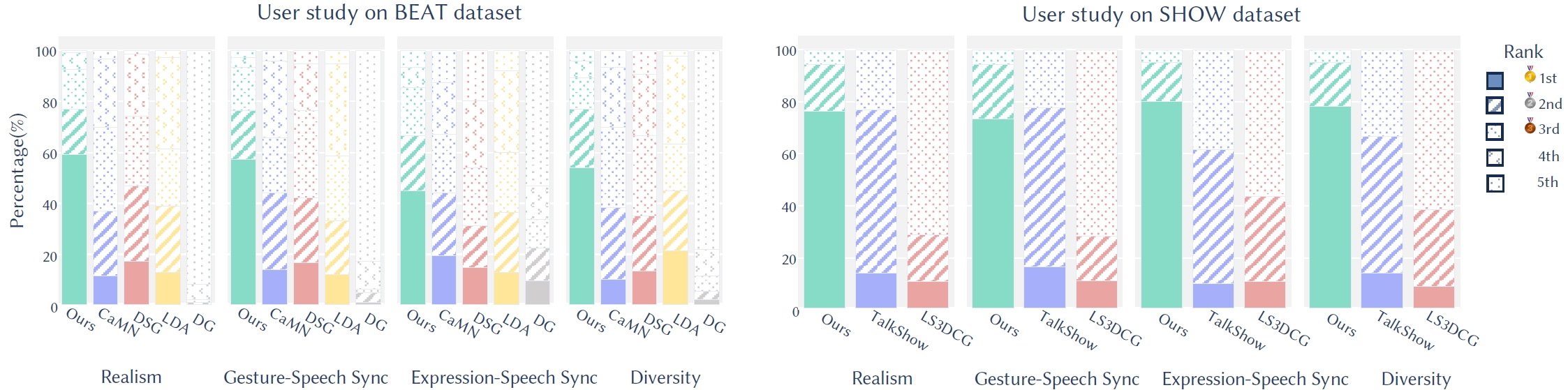
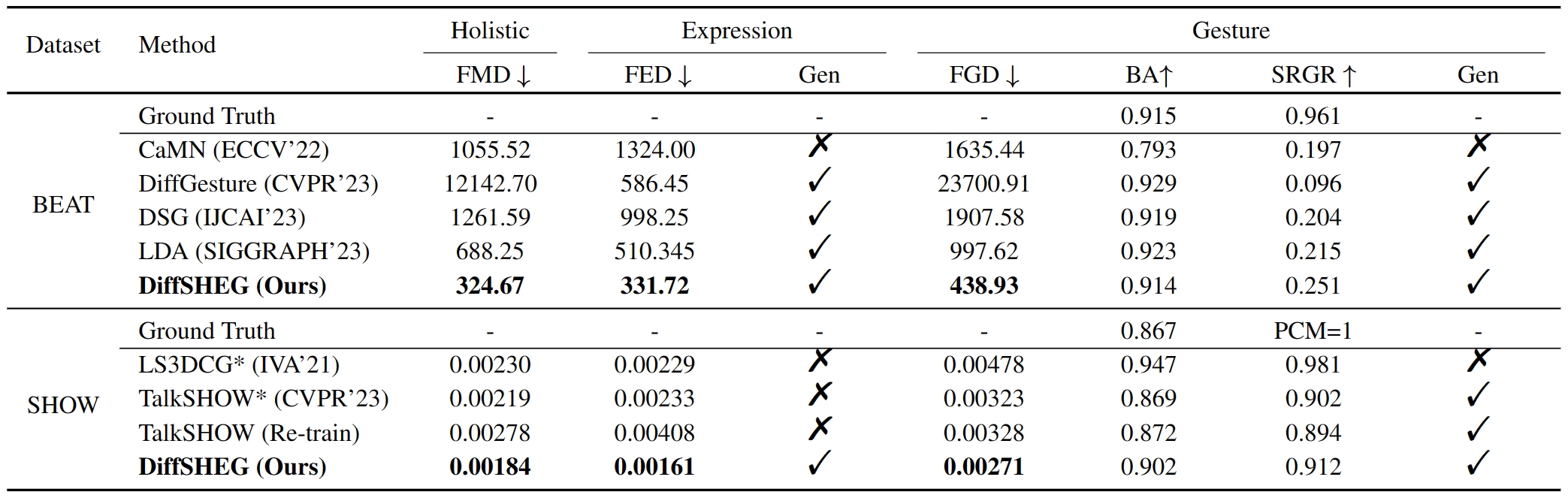
Framework
DiffSHEG framework overview. Left: Audio Encoders and UniEG-Transformer Denoiser. Given an audio clip, we encode the audio into a low-level feature Mel-Spectrogram and a high-level HuBERT feature. The audio features are concatenated with other optional conditions, such as text, and then fed into the UniEG Transformer Denoiser. The denoising block fuses the conditions with noisy motion at diffusion step t and feeds it into style-aware transformers to get the predicted noises. The uni-directional condition flow is enforced from expression to gesture. Right: The detailed architecture of style-aware Transformer encoder and motion-condition fusion residual block.